
Hinweise zur Datenanalyse und Fehlerrechnung
Obwohl man sich am Anfang des zweiten Semesters normalerweise eine Vorlesung zur Datenanalyse und Fehlerrechnung anhört, ist man danach trotzdem noch nicht unbedingt in der Lage, selbst seine Messdaten auszuwerten. Deshalb hier einige Hinweise zur Vorgehensweise:
Bevor man sich über die Fehler Gedanken macht, sollte man erst einmal die normale Auswertung der Messergebnisse machen, also aus den gemessenen Werten die gesuchten Größen ausrechnen. Dann muss man sich zunächst klar werden, welche Art von Fehlern vorliegt.
Systematische Fehler
Ein systematischer Fehler ist i.d.R. ein Fehler, der durch Fehler bei Planung, Aufbau oder Durchführung des Experimentes hervorgerufen wird. Systematische Fehler erkennt man daran, dass sie reproduzierbar sind, d.h. bei wiederholter Messung, auch unter leicht abgeänderten Randbedingungen ist der Fehler immer gleich groß und hat immer das gleiche Vorzeichen. Beispiele sind:
- Innenwiderstand eines Volt- oder Amperemeters
- Bei Thermodynamikversuchen geht durch Wärmeaustausch mit der Umgebung Energie verloren.
- Bei Thermodynamikversuchen wurde vor einer Temperaturmessung nicht die Einstellung des thermodynamischen Gleichgewichts abgewartet (z.B. beim Versuch ZUS des Anfängerpraktikums).
- Eine Waage wurde vor der Wägung nicht auf 0 gestellt (Nullpunktsfehler).
- Näherungen bei der Rechnung
Statistische Fehler
Statistische Fehler treten auf, ohne dass ihre Ursache im Nachhinein noch festgestellt werden könnte. Man erkennt sie daran, dass sie bei wiederholter Messung zufällig schwanken. Während ein systematischer Fehler das Ergebnis immer in die gleiche Richtung verfälscht, ist der statistische Fehler zufällig um den exakten Wert herum gestreut. Beispiele sind:
- Die Auflösungsgrenze eines Messgerätes (d.h. Anzahl angezeigter Stellen oder Genauigkeit der Skaleneinteilung)
- Bei wiederholter Messung unter gleichen Bedingungen die zufällige Streuung der Werte um ihren Mittelwert.
- Unvorhersehbare Schwankungen des Messwertes ("Hintergrundrauschen"). Z.B. schwankt bei Verwendung relativ genauer Messgeräte oft die letzte Stelle unkontrollierbar hin und her.
- Bei Versuchen mit Radioaktivität die zufälligen Schwankungen der Zerfallsrate auf Grund des statistischen Natur des Prozesses
Natürlich ist die Einteilung der Fehler in statistische und systematische Beiträge nicht immer eindeutig und es gibt einen gewissen Spielraum. So wurden beispielsweise bei vielen unserer Ausarbeitungen Fehler als systematisch deklariert, obwohl sie eigentlich eher statistischer Natur sind. Die Betreuer haben das bei der Korrektur i.d.R. akzeptiert.
Fehlerfortpflanzung
Um die Auswirkungen eines Messfehlers auf die Endergebnisse abschätzen zu können, verwendet man die Fehlerfortpflanzungsformeln. Allgemein berechnet man die Fehlerfortpflanzung für systematische und statistische Beiträge getrennt.
Für systematische Fehler nimmt man das lineare Fehlerfortpflanzungsgesetz:
Hängt das Endergebnis mit den Messgrößen über eine
Funktion  zusammen, so
lautet es
zusammen, so
lautet es
![]()
Für die statistischen Fehler verwendet man die Gauß'sche (oder quadratische) Fehlerfortpflanzungsformel
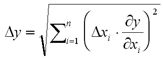
Sowohl für lineare als auch für Gauß'sche Fehlerforpflanzung muss mit abosulten Fehlern gerechnet werden. Die sogenannten "vereinfachten Formeln" für bestimmte Arten von Problemen, die im Skript zur Fehlerrechnungsvorlesung angegeben sind, verwenden relative Fehler (d.h. Prozentangaben). Von diesen Formeln sollte man generell die Finger lassen, da sie mehr Verwirrung stiften als nutzen.
Nach diesem Schema erhält man schließlich getrennt einen linearen und einen systematischen Fehler des Endergebnisses. Diese beiden Werte addiert man einfach zusammen und erhält so den Gesamtfehler.
Bei vielen Praktikumsversuchen sind entweder die statistischen oder die systematischen Fehler so klein, dass sie ganz vernachlässigt werden können. Oft kann man sie auch schon vor der Fehlerrechnung zusammenfassen und dann die Fehlerfortpflanzungsformel für die überwiegende Art von Fehlern anwenden. Das vereinfach die Rechnung natürlich erheblich.
Regressionsgeraden
Da man bei der Auswertung von Experimenten oft mit linearen Zusammenhängen zwischen zwei Größen zu tun hat, bieten sich Regressionsgeraden als Hilfsmittel zur Datenanalyse an. Unter Regression versteht man ein mathematisches Verfahren zu vorgegebenen Messpunkten diejenige Gerade zu finden, die die Messwerte am besten annähert.
Am einfachsten lässt man die Regressionsgerade von einem geeigneten Programm wie Gnumeric (siehe unter Tipps & Tricks) berechnen. Dazu muss man die Werte für die sogenannte unabhängige Variable (im Diagramm normalerweise die x-Richtung) und die abhängige Variable (y-Richtung) vorgeben. Der Regressionsalgorithmus geht davon aus, dass die Werte für die unabhängige Variable exakt sind, deshalb sollte man dafür die Messgröße mit dem geringeren Fehler wählen.
Man erhält Werte für Steigung und Achsenabschnitt, die die Regressionsgerade eindeutig festlegen, sowie die statistischen Fehler (Standardabweichungen) dieser beiden Koeffizienten.
Regressionsgeraden eignen sich sehr gut zur Elimination von systematischen Fehlern. Bei den meisten Versuchen ist man nur an der Steigung der Geraden interessiert, so dass man bei der Fehlerrechnung all die Fehler vernachlässigen kann, die nur eine Parallelverschiebung bewirken. Da fast alle systematischen Fehlerquellen diese Eigenschaft haben, kann man für die weitere Fehlerrechnung getrost alle systematischen Fehler vernachlässigen und nur mit den statistischen rechnen.