This chapter describes the operating concepts and maintenance tasks of the batch queuing system, LSF Batch. This chapter requires you to understand concepts from `Managing LSF Base' on page 45. The topics covered in this chapter are:
Each batch job has its resource requirements. Batch server hosts that match the resource requirements are the candidate hosts. When the batch daemon wants to schedule a job, it first asks the LIM for the load index values of all the candidate hosts. The load values for each host are compared to the scheduling conditions. Jobs are only dispatched to a host if all load values are within the scheduling thresholds.
When a job is running on a host, the batch daemon periodically gets the load information for that host from the LIM. If the load values cause the suspending conditions to become true for that particular job, the batch daemon performs the SUSPEND action to the process group of that job. The batch daemon allows some time for changes to the system load to register before it considers suspending another job.
When a job is suspended, the batch daemon periodically checks the load on that host. If the load values cause the scheduling conditions to become true, the daemon performs the RESUME action to the process group of the suspended batch job.
The SUSPEND and RESUME actions are configurable as described in `Configurable Job Control Actions' on page 228.
LSF Batch has a wide variety of configuration options. This section describes only a few of the options to demonstrate the process. For complete details, see `LSF Batch Configuration Reference' on page 193. The algorithms used to schedule jobs and concepts involved are described in `How LSF Batch Schedules Jobs' on page 19.
LSF is often used on systems that support both interactive and batch users. On one hand, users are often concerned that load sharing will overload their workstations and slow down their interactive tasks. On the other hand, some users want to dedicate some machines for critical batch jobs so that they have guaranteed resources. Even if all your workload is batch jobs, you still want to reduce resource contentions and operating system overhead to maximize the use of your resources.
Numerous parameters in LIM and LSF Batch configurations can be used to control your resource allocation and to avoid undesirable contention.
Since interferences are often reflected from the load indices, LSF Batch responds to load changes to avoid or reduce contentions. LSF Batch can take actions on jobs to reduce interference before or after jobs are started. These actions are triggered by different load conditions. Most of the conditions can be configured at both the queue level and at the host level. Conditions defined at the queue level apply to all hosts used by the queue, while conditions defined at the host level apply to all queues using the host.
SUSPEND action is performed to a running job. STOP_COND as described in `The lsb.queues File' on page 208, or as suspending load threshold as described in `Load Thresholds' on page 216. At the host level, suspending conditions are defined as stop load threshold as described in `The lsb.hosts File' on page 202.
RESUME action is performed on a suspended job. RESUME_COND, or the scheduling load conditions if RESUME_COND is not defined.
To effectively reduce interference between jobs, correct load indices should be used properly. Below are examples of a few frequently used parameters.
The paging rate (pg) load index relates strongly to the perceived interactive performance. If a host is paging applications to disk, the user interface feels very slow.
The paging rate is also a reflection of a shortage of physical memory. When an application is being paged in and out frequently, the system is spending a lot of time performing overhead, resulting in reduced performance.
The paging rate load index can be used as a threshold to either stop sending more jobs to the host, or to suspend an already running batch job so that interactive users will not be interfered.
This parameter can be used in different configuration
files to achieve different purposes. By defining paging rate threshold in lsf.cluster.cluster,
the host will become busy from LIM's point of view; therefore, no more jobs
will be advised by LIM to run on this host.
By including paging rate in LSF Batch queue or host scheduling conditions, batch jobs can be prevented from starting on machines with a heavy paging rate, or can be suspended or even killed if they are interfering with the interactive user on the console.
A batch job suspended due to pg threshold will not be resumed even if the resume conditions are met unless the machine is interactively idle for more than PG_SUSP_IT seconds, as described in `Parameters' on page 193.
Strict control can be achieved using the idle time (it) index. This index measures the number of minutes since any interactive terminal activity. Interactive terminals include hard wired ttys, rlogin and lslogin sessions, and X shell windows such as xterm. On some hosts, LIM also detects mouse and keyboard activity.
This index is typically used to prevent batch jobs from interfering with interactive activities. By defining the suspending condition in LSF Batch queue as `it==0 && pg >50', a batch job from this queue will be suspended if the machine is not interactively idle and paging rate is higher than 50 pages per second. Furthermore, by defining resuming condition as `it>5 && pg <10' in the queue, a suspended job from the queue will not resume unless it has been idle for at least five minutes and the paging rate is less than ten pages per second.
The it index is only non-zero if no interactive users are active. Setting the it threshold to five minutes allows a reasonable amount of think time for interactive users, while making the machine available for load sharing, if the users are logged in but absent.
For lower priority batch queues, it is appropriate to set an it scheduling threshold of ten minutes and suspending threshold of two minutes in the lsb.queues file. Jobs in these queues are suspended while the execution host is in use, and resume after the host has been idle for a longer period. For hosts where all batch jobs, no matter how important, should be suspended, set a per-host suspending threshold in the lsb.hosts file.
Running more than one CPU-bound process on a machine (or more than one process per CPU for multiprocessors) can reduce the total throughput because of operating system overhead, as well as interfering with interactive users. Some tasks such as compiling can create more than one CPU intensive task.
Batch queues should normally set CPU run queue scheduling thresholds below 1.0, so that hosts already running compute-bound jobs are left alone. LSF Batch scales the run queue thresholds for multiprocessor hosts by using the effective run queue lengths, so multiprocessors automatically run one job per processor in this case. For concept of effective run queue lengths, see lsfintro(1).
For short to medium-length jobs, the r1m index should be used. For longer jobs, you might want to add an r15m threshold. An exception to this are high priority queues, where turnaround time is more important than total throughput. For high priority queues, an r1m scheduling threshold of 2.0 is appropriate.
The ut parameter measures the amount of
CPU time being used. When all the CPU time on a host is in use, there is little
to gain from sending another job to that host unless the host is much more powerful
than others on the network. The lsload command reports ut
in percent, but the configuration parameter in the lsf.cluster.cluster
file and the LSF Batch configuration files is set as a fraction in the range
from 0 to 1. A ut threshold of 0.9 prevents jobs from going to
a host where the CPU does not have spare processing cycles.
If a host has very high pg but low ut, then it may be desirable to suspend some jobs to reduce the contention.
The commands bhist and bjobs are useful for tuning batch queues. bhist shows the execution history of batch jobs, including the time spent waiting in queues or suspended because of system load. bjobs -p shows why a job is pending.
A batch job is suspended when the load level of the execution host causes the suspending condition to become true. The bjobs -lp command shows the reason why the job was suspended together with the scheduling parameters. Use bhosts -l to check the load levels on the host, and adjust the suspending conditions of the host or queue if necessary.
The bhosts -l gives the most recent load values used for the scheduling of jobs.
% bhosts -l hostB
HOST: hostB
STATUS CPUF JL/U MAX NJOBS RUN SSUSP USUSP RSV DISPATCH_WINDOWS
ok 20.00 2 2 0 0 0 0 0 -
CURRENT LOAD USED FOR SCHEDULING:
r15s r1m r15m ut pg io ls t tmp swp mem
Total 0.3 0.8 0.9 61% 3.8 72 26 0 6M 253M 297M
Reserved 0.0 0.0 0.0 0% 0.0 0 0 0 0M 0M 0M
LOAD THRESHOLD USED FOR SCHEDULING:
r15s r1m r15m ut pg io ls it tmp swp mem
loadSched - - - - - - - - - - -
loadStop - - - - - - - - - - -
A `-' in the output indicates that the particular threshold is not defined. If no suspending threshold is configured for a load index, LSF Batch does not check the value of that load index when deciding whether to suspend jobs. Normally, the swp and tmp indices are not considered for suspending jobs, because suspending a job does not free up the space being used. However, if swp and tmp are specified by the STOP_COND parameter in your queue, these indices are considered for suspending jobs.
The load indices most commonly used for suspending conditions are the CPU run queue lengths, paging rate, and idle time. To give priority to interactive users, set the suspending threshold on it load index to a non-zero value. Batch jobs are stopped (within about 1.5 minutes) when any user is active, and resumed when the host has been idle for the time given in the it scheduling condition.
To tune the suspending threshold for paging rate, it is desirable to know the behaviour of your application. On an otherwise idle machine, check the paging rate using lsload, and then start your application. Watch the paging rate as the application runs. By subtracting the active paging rate from the idle paging rate, you get a number for the paging rate of your application. The suspending threshold should allow at least 1.5 times that amount. A job can be scheduled at any paging rate up to the scheduling threshold, so the suspending threshold should be at least the scheduling threshold plus 1.5 times the application paging rate. This prevents the system from scheduling a job and then immediately suspending it because of its own paging.
The effective CPU run queue length condition should be configured like the paging rate. For CPU-intensive sequential jobs, the effective run queue length indices increase by approximately one for each job. For jobs that use more than one process, you should make some test runs to determine your job's effect on the run queue length indices. Again, the suspending threshold should be equal to at least the scheduling threshold plus 1.5 times the load for one job.
Suspending thresholds can also be used to enforce inter-queue priorities. For example, if you configure a low-priority queue with an r1m (1 minute CPU run queue length) scheduling threshold of 0.25 and an r1m suspending threshold of 1.75, this queue starts one job when the machine is idle. If the job is CPU intensive, it increases the run queue length from 0.25 to roughly 1.25. A high-priority queue configured with a scheduling threshold of 1.5 and an unlimited suspending threshold will send a second job to the same host, increasing the run queue to 2.25. This exceeds the suspending threshold for the low priority job, so it is stopped. The run queue length stays above 0.25 until the high priority job exits. After the high priority job exits the run queue index drops back to the idle level, so the low priority job is resumed.
By default, LSF Batch schedules user jobs according to the First-Come-First-Serve (FCFS) principle. If your sites have many users contending for limited resources, the FCFS policy is not enough. For example, a user could submit 1000 long jobs in one morning and occupy all the resources for a whole week, while other users's urgent jobs wait in queues.
LSF Batch provides fairshare scheduling to give you control on how resources should be shared by competing users. Fairshare can be configured so that LSF Batch can schedule jobs according to each user or user group's configured shares. When fairshare is configured, each user or user group is assigned a priority based on the following factors:
HIST_HOURS parameter in the lsb.params file)
If a user or group has used less than their share of the processing resources, their pending jobs (if any) are scheduled first, jumping ahead of other jobs in the batch queues. The CPU times used for fairshare scheduling are not normalised for the host CPU speed factors.
The special user names others and default can also be assigned shares. The name others refers to all users not explicitly listed in the USER_SHARES parameter. The name default refers to each user not explicitly named in the USER_SHARES parameter. Note that default represents a single user name while others represents a user group name.
Fairshare affects job scheduling only if there are resource contentions among users such that users with more shares will run more jobs than users with less shares. If there is only one user having jobs to run, then fairshare has no effect on job scheduling.
Fairshare in LSF Batch can be configured at either queue level or host level. At queue level, the shares apply to all users who submit jobs to the queue and all hosts that are configured as hosts for the queue. It is possible that several queues share some hosts as servers, but each queue can have its own fairshare policy.
Queue level fairshare is defined using the keyword FAIRSHARE.
If you want strict resource allocation control on some hosts for all workload, configure fairshare at the host level. Host level fairshare is configured as a host partition. Host partition is a configuration option that allows a group of server hosts to be shared by users according to configured shares. In a host partition each user or group of users is assigned a share. The bhpart command displays the current cumulative CPU usage and scheduling priority for each user or group in a host partition.
Below are some examples of configuring fairshare at both queue level and host level. Details of the configuration syntax are described in `Host Partitions' on page 206 and `Scheduling Policy' on page 221.
Do not define fairshare at both the host and the queue level if the queue uses some or all hosts belonging to the host partition, because this results in policy conflicts. Doing so will result in undefined scheduling behaviour.
If you have a queue that is shared by critical users and non-critical users, you can configure fairshare so that as long as there are jobs from key users waiting for resource, non-critical users' jobs will not be dispatched.
First you can define a user group key_users in lsb.users file. You can then define your queue such that FAIRSHARE is defined:
Begin Queue
QUEUE_NAME = production
FAIRSHARE = USER_SHARES[[key_users@, 2000] [others, 1]]
...
End Queue
By this configuration, key_users each have 2000 shares, while other users together have only 1 share. This makes it virtually impossible for other users' jobs to get dispatched unless no user in the key_users group has jobs waiting to run.
Note that a user group followed by an `@' refers to each user in that group, as you could otherwise configure by listing every user separately, each having 2000 shares. This also defines equal shares among the key_users. If `@' is not present, then all users in the user group share the same share and there will be no fairshare among them.
You can also use host partition to achieve similar results if you want the same fairshare policy to apply to jobs from all queues.
Suppose two departments contributed to the purchase of a large system. The engineering department contributed 70 percent of the cost, and the accounting department 30 percent. Each department wants to get (roughly) their money's worth from the system.
You would configure two user groups in the lsb.users file, one listing all the users in the engineering group, and one listing all the members in the accounting group:
Begin UserGroup
Group_Name Group_Member
eng_users (user6 user4)
acct_users (user2 user5)
End UserGroup
You would then configure a host partition for the host, listing the appropriate shares:
Begin HostPartition
HPART_NAME = big_servers
HOSTS = hostH
USER_SHARES = [eng_users, 7] [acct_users, 3]
End HostPartition
Note the difference in defining USER_SHARES in a queue and in a host partition. Alternatively, the shares can be configured for each member of a user group by appending an `@' to the group name:
USER_SHARES = [eng_users@, 7] [acct_users@, 3]
If a user is configured to belong to two user groups, the user can specify which group the job belongs to with the -P option to the bsub command.
Similarly, you can define the same policy at the queue level if you want to enforce this policy only within a queue.
Round-robin scheduling balances the resource usage between users by running one job from each user in turn, independent of what order the jobs arrived in. This can be configured by defining an equal share for everybody. For example:
Begin HostPartition
HPART_NAME = even_share
HOSTS = all
USER_SHARES = [default, 1]
End HostPartition
For both queues and host partitions, the specification of how resources are allocated to users can be performed in a hierarchical manner. Groups of users can collectively be allocated a share, and that share can be further divided and given to subgroups, resulting in a share tree. For a discussion of the terminology associated with hierarchical fairsharing, see `Hierarchical Fairshare' on page 60 of the LSF Batch User's Guide.
There are two steps in configuring hierarchical fairshare:
lsb.users
USER_SHARES definition of the queue or host partition.
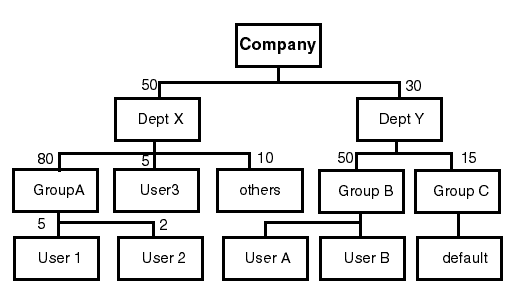
The following example shows how you can configure a share tree in the lsb.users file. User groups must be defined in the share tree before they can be used (in the GROUP_MEMBER column) to define other groups. The USER_SHARES column describes how the shares are distributed in a hierachical manner.
Begin UserGroup
GROUP_NAME GROUP_MEMBER USER_SHARES
GroupA (User1 User2) ([User1, 5] [User2, 2])
GroupB (UserA UserB) ()
GroupC (UserC UserD UserE UserF) ([default, 1])
DeptX (GroupA User3 User4 User5) ([GroupA, 80] [User3, 5] [others, 10])
DeptY (GroupB GroupC) ([GroupB, 50] [GroupC, 15])
Company (DeptX DeptY) ([DeptX, 50] [DeptY, 30])
End UserGroup
The share distribution tree described by the preceding configuration is shown below.
There are a few special cases in the above tree that should be noted. The keyword "others" is used to refer to a special group representing all other users in GroupA that are not explicitly listed in the share allocation. For example, DeptX subdivides its shares among GroupA, User3 and "others".
In the above example, there is no definition of how users in group "others" should divide the shares. Also note that there is no specification of how users in groupB should subdivide the shares. If share distribution is not defined for a group, all members of the group collectively own the shares. In this case group members compete for resources allocated to the group on a First-Come-First-Serve (FCFS) basis.
To implement equal share at the group level, you should define USER_SHARES for the group as "[default, 1]", as is the case with GroupC in the above example.
The hierarchical shares defined in lsb.users file have no effect unless the group names are referenced in a share provider's USER_SHARES definition.
To associate the share tree defined by the above in a share provider (queue or host partition) simply use the group in the USER_SHARES definition.
The following example shows how a host partition might use the share tree "company" in its definition:
Begin HostPartition
HPART_NAME = hpartest
HOSTS = all
USER_SHARES = ([company, 1])
End HostPartition
The USER_SHARES parameter in the host partition definition references the top-level group of the share tree. Each share provider will maintain a copy of the share tree and adjust the priority of users based on the resource consumption of jobs using the provider. This might result in, for example, a user having a low priority in one fairshare queue and a high priority in another queue, even though the static shares they have been allocated are the same.
If hierarchical fairshare is not required, the USER_SHARES parameter in the UserGroup section of the lsb.users file can be omitted and the USER_SHARE parameter in the queue or host partition can directly list the shares. In this case, the share tree is essentially flat, and the share assigned to any group cannot be further divided.
LSF Batch uses an account to maintain information about shares and resource consumption of every user or user group. Each account keeps the following information:
u_share)
run_j)
HIST_HOURS hours (cpu_t)
run_t).
LSF Batch uses a decay factor in calculating the cumulative CPU time cpu_t. This decay factor scales the CPU time used by jobs so that recently used CPU time is weighted more heavily than CPU time used in the distant past. The decay factor is set such that one hour of CPU time used recently is decayed to 0.1 hours after HIST_HOURS hours. See `The lsb.params File' on page 193 for the definition of HIST_HOURS.
A dynamic priority is calculated for each account according to the following formula:
priority = u_share
/(0.01 + cpu_t*CPU_TIME_FACTOR + run_t*RUN_TIME_FACTOR + run_j*RUN_JOB_FACTOR)
where CPU_TIME_FACTOR, RUN_TIME_FACTOR, and RUN_JOB_FACTOR are system-wide configuration parameters defined in lsb.params file. See `The lsb.params File' on page 193 for a description and default values for these parameters. These parameters allow for customization of the fairshare formula to ignore or give greater weight to certain terms. For example, if you want to implement static fairshare so that priority is determined by shares only, then you can set all factors as 0.
Dynamic priorities are recalculated whenever a variable in the above formula is changed.
LSF Batch dispatches jobs according to their dynamic priorities. If fairshare is defined at the queue level, the priorities are local to each queue. Among queues, the queue priorities decide which queue should be scanned first. If fairshare is defined at host level through a host partition, then the priorities of users are global across all queues that use hosts in the host partitions to run jobs. In this case, queue priority has no effect because the order is determined by users' current priorities with regard to the host partition.
Whenever a host becomes available to run a job, LSF Batch tries to dispatch a job of the user with the highest dynamic priority. As soon as a job is dispatched, the user's run_j gets updated and thus the priority gets lowered according to the above formula. In the case of hierarchical fairshare, LSF Batch scans the share tree from the top level down to find out which user's job to run next. For example, with the share tree shown by Figure 8, LSF Batch first decides which department has the highest dynamic priority, then further decides which group has the highest priority. After selecting the highest priority group, a user with the highest priority within the group will be selected. If this user has a job to run, the job will be dispatched, else the user with the next highest priority will be considered, and so on.
Suppose User1 is chosen and the job has been started; the priorities of User1, GroupA, and DeptX are immediately updated to reflect the change of variable run_j at all levels.
In some special cases, a user could belong to two or more groups simultaneously. This is the case when a user works for several groups at the same time. Thus it is possible to define a share tree with one user appearing multiple times in the same share tree. In this case, the user's priority is determined by the highest priority node the user belongs to. To override this behaviour, a user can use the "-G" option of the bsub to advise LSF Batch which user group this user should belong to when dispatching this job.
Although LSF Batch makes it easier for users to access all resources of your client, real life constraints require that certain resources be controlled such that users are not stepping on one another. LSF Batch provides ways for you as an administrator to enforce controls in different ways.
The concept of dispatch and run windows for LSF Batch are described in `How LSF Batch Schedules Jobs' on page 19.
This can be achieved by configuring dispatch windows for the host in the lsb.hosts files, and run windows and dispatch windows for queues in lsb.queues file.
Dispatch windows in lsb.hosts file cause batch server hosts to be closed unless the current time is inside the time windows. When a host is closed by a time window, no new jobs will be sent to it, but the existing jobs running on it will remain running. Details about this parameter are described in `Host Section' on page 202.
Dispatch and run windows defined in lsb.queues limit when a queue can dispatch new jobs and when jobs from a queue are allowed to run. A run window differs from a dispatch window in that when a run window is closed, jobs that are already running will be suspended instead of remain running. Details of these two parameters are described in `The lsb.queues File' on page 208.
By defining different job slot limits to hosts, queues, and users, you can control batch job processing capacity for your cluster, hosts, and users. For example, by limiting maximum job slot for each of your hosts, you can make sure that your system operates at optimal performance. By defining a job slot limit for some users, you can prevent some users from using up all the job slots in the system at one time. There are a variety of job slot limits that can be used for very different purposes. See `Job Slot Limits' on page 26 for more concepts and descriptions of job slot limits. Configuration parameters for job slot limits are described in `LSF Batch Configuration Reference' on page 193.
Resource limits control how much resource can be consumed by jobs. By defining such limits, the cluster administrator can have better control of resource usage. For example, by defining a high priority short queue, you can allow short jobs to be scheduled earlier than long jobs. To prevent some users from submitting long jobs to this short queue, you can set CPU limit for the queue so that no jobs submitted from the queue can run for longer than that limit.
Details of resource limit configuration are described in `Resource Limits' on page 217.
Most of the Batch policies discussed above support competition based scheduling; that is, users competing for resources on a dynamic basis. It is sometimes desirable to have reservation based scheduling so that people can predict the timing of their jobs.
The concept of resource reservation is discussed in `Resource Reservation' on page 39.
The resource reservation feature at the queue level allows the cluster administrator to specify the amount of resources the system should reserve for jobs in the queue. It also serves as the upper limits of resource reservation if a user also specifies it when submitting a job.
The resource reservation requirement can be configured at the queue level as part of the queue level resource requirements. For example:
Begin Queue
.
RES_REQ = select[type==any] rusage[swap=100:mem=40:duration=60]
.
End Queue
will allow a job to be scheduled on any host that the queue is configured to use and will reserve 100 megabytes of swap and 40 megabytes of memory for a duration of 60 minutes. See `Queue-Level Resource Requirement' on page 213 for detailed configuration syntax for this parameter.
The concepts of processor reservation and backfilling were described in `Processor Reservation' on page 39. You might want to configure processor reservation if your cluster has a lot of sequential jobs that compete for resources with parallel jobs.
Parallel jobs requiring a large number of processors can often not be started if there are many lower priority sequential jobs in the system. There might not be enough resources at any one instant to satisfy a large parallel job, but there might be enough to allow a sequential job to be started. With the processor reservation feature the problem of starvation of parallel jobs can be reduced.
A host can have multiple `slots' available for the execution of jobs. The number of slots can be independent of the number of processors and each queue can have its own notion of the number of execution slots available on each host. The number of execution slots on each host is controlled by the PJOB_LIMIT and HJOB_LIMIT parameters defined in lsb.queues file. For details of these parameters defined in lsb.queues file, see `The lsb.queues File' on page 208. When attempting to schedule parallel jobs requiring N processors (as specified via bsub -n), the system will attempt to find N execution slots across all eligible hosts. It ensures that each job never receives more slots than there are physical processors on any individual host.
When a parallel job cannot be dispatched because there are not enough execution slots to satisfy its minimum processor requirements, the currently available slots will be reserved for the job. These reserved job slots are accumulated until there are enough available to start the job. When a slot is reserved for a job it is unavailable to any other job.
While processors are being reserved by a parallel job, they cannot be used by other jobs. However, there are situations where the system can determine that the job reserving the processors cannot start before a certain time. In this case it makes sense to run another job that is short enough to fit into the time slot during which the processors are reserved but not used. This notion is termed backfilling. Short jobs are said to backfill processors reserved for large jobs. Backfilling requires that users specify how long each job will run so that LSF Batch can estimate when it will start and complete. Backfilling, together with processor reservation, allows large parallel jobs to run while not underutilizing resources.
For the backfill policy to work effectively, each job should have a run limit specified (via -W bsub option). In order to enforce that users should specify this option, the external submission executable, esub, can be used. See `Validating Job Submissions' on page 91.
When backfilling is enabled, the system will compute the estimated start time for each job based on the run limits of the currently started jobs. A given job (jobA) can backfill the reserved processors of another job (jobB) if there is sufficient time for jobA to complete, based on its run limit, before the estimated start time of jobB.
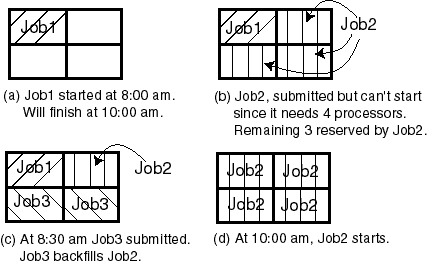
As an example, consider the sequence of events depicted in the Figure 9. `Example of Backfilling' on page 125. In this scenario, assume the cluster consists of a 4-CPU multiprocessor host. A sequential job (job1) with a run limit of two hours is submitted to a high priority queue and gets started at 8:00 am (figure (a)). Shortly afterwards, a parallel job (job2) requiring all four CPUs is submitted. It cannot start right away because of job1, so it reserves the remaining three processors (figure (b)). At 8:30 am, another parallel job (job3) is submitted requiring only two processors and with a run limit of one hour. Since job2 cannot start until 10:00am (when job1 finishes), its reserved processors can be backfilled by job3 (figure (c)). Therefore job3 can complete before job2's start time, making use of the idle processors. If job3's run limit was three hours, for example, it would not be able to backfill job2's reserved slots. Job 3 will finish at 9:30am and job1 at 10:00am, allowing job2 to start shortly after 10:00am.
The estimated start time of a job can be displayed using the bjobs -l command or by viewing the detailed information about the job through xlsbatch.
Figure 9. Example of Backfilling
See `Processor Reservation for Parallel Jobs' on page 211 and `Backfill Scheduling' on page 211 for configuration options for this feature.
When LSF Batch runs your jobs, it tries to make it as transparent to the user as possible. By default, the execution environment is maintained to be as close to the current environment as possible. LSF Batch will copy the environment from the submission host to the execution host. It also sets the umask and the current working directory.
Since a network can be heterogeneous, it is often impossible or undesirable to reproduce the submission host's execution environment on the execution host. For example, if home directory is not shared between submission and execution host, LSF Batch runs the job in the /tmp on the execution host. If the DISPLAY environment variable is something like `Unix:0.0', or `:0.0', then it must be processed before using on the execution host. These are automatically handled by LSF Batch.
Users can change the default behaviour by using a job starter, or by using the `-L' option of the bsub command to change the default execution environment. See `Queue-Level Job Starters' on page 129 for detailed information on using a job starter at the queue level.
For resource control purpose, LSF Batch also changes some of the execution environment of jobs. These include nice values, resource limits, or any other environment by configuring a job starter.
In addition to environment variables inherited from the user, LSF Batch also sets a few more environment variables for batch jobs. These are:
LSB_JOBID: Batch job ID assigned by LSF Batch.
LSB_JOBINDEX: Index of the job that belongs to a job array.
LSB_CHKPNT_DIR: This variable is set each time a checkpointed job is submitted. The value of the variable is chkpntdir/jobId, a subdirectory of the checkpoint directory that is specified when the job is submitted. The subdirectory is identified by the job ID of the submitted job.
LSB_HOSTS: The list of hosts that are used to run the batch job. For sequential jobs, this is only one host name. For parallel jobs, this includes multiple host names.
LSB_QUEUE: The name of the queue the job belongs to.
LSB_JOBNAME: Name of the job.
LSB_RESTART: Set to `Y' if the job is a restarted job or if the job has been migrated. Otherwise this variable is not defined.
LSB_EXIT_PRE_ABORT: Set to an integer value representing an exit status. A pre-execution command should exit with this value if it wants the job to be aborted instead of requeued or executed.
LSB_EXIT_REQUEUE: Set to the REQUEUE_EXIT_VALUES parameter of the queue. This variable is not defined if REQUEUE_EXIT_VALUES is not configured for the queue.
LSB_JOB_STARTER: Set to the value of the job starter if a job starter is defined for the queue.
LSB_INTERACTIVE: Set to `Y' if the job is submitted with -I option. Otherwise, it is undefined.
LS_JOBPID: Set to the process ID of the job.
LS_SUBCWD: This is the directory on the submission when the job was submitted. This is different from PWD only if the directory is not shared across machines or when the execution account is different from the submission account as a result of account mapping.
-L option of bsub can be used to reinitialize the environment variables. If submitting a job from a UNIX machine to an NT machine, you can set the environment variables explicitly in your job script. Alternatively, the Job Starter feature can be used to reset the environment variables before starting the job.
LSF automatically resets thePATHon the execution host if the submission host is of a different type. If the submission host is NT and the execution host is UNIX, thePATHvariable is set to/bin:/usr/bin:/sbin:/usr/sbinandLSF_BINDIR(if defined inlsf.conf) is appended to it. If the submission host is UNIX and the execution host is NT, thePATHvariable is set to the systemPATHvariable withLSF_BINDIRappended to it. LSF looks for the presence of theWINDIRvariable in the job's environment to determine whether the job was submitted from an NT or UNIX host. IfWINDIRis present, it is assumed that the submission host was NT; otherwise, the submission host is assumed to be a UNIX machine.
LSF transfers most environment variables between submission and execution hosts. The following environment variables are overridden based on the values on the execution host:COMPSPEC
COMPUTERNAME
NTRESKIT
OS2LIBPATH
PROCESSOR_ARCHITECTURE
PROCESSOR_LEVEL
SYSTEMDRIVE
SYSTEMROOT
WINDIRThese must be defined as system environment variables on the execution host.
If the
WINDIRon the submission and execution host are different, then the systemPATHvariable on the execution host is used instead of that from the submission host.Avoid using drive names in environment variables (especially the
%PATHvariable) for drives that are connected over the network. It is preferable to use the UNC form of the path. This is because drive maps are shared between all users logged on to a particular machine. For example, if an interactive user has driveF:mapped to\\serverX\share, then any batch job will also see driveF:mapped to\\serverX\share. However, driveF:might have been mapped to a different share on the submission host of the job.The Job Starter feature can be used to perform more site-specific handling of environment variables. See `Job Starters' on page 16 for more details.
Many LSF tools use LSF Remote Execution Server (RES)
to run jobs such as lsrun, lsmake, lstcsh,
and lsgrun. You can control the execution priority of jobs started
via RES by modifying your LIM configuration file lsf.cluster.cluster.
This can be done by defining the REXPRI parameter for individual
hosts. See `Descriptive Fields' on page 182
for details of this parameter.
LSF Batch jobs can be run with a nice value as defined in your lsb.queues file. Each queue can have a different nice value. See `NICE = integer' on page 209 for details of this parameter.
Your batch jobs can be accompanied with a pre-execution and a post-execution command. This can be used for many purposes. For example, you can use these commands to create or delete scratch directories, or check for necessary conditions before running the real job. Details of these concepts are described in `Pre- and Post-execution Commands' on page 36.
The pre-execution and post-execution commands can be configured at the queue level as described in `Queue-Level Pre-/Post-Execution Commands' on page 224.
Some jobs have to be started in a particular environment, or require some type of setup to be performed before they are executed. In a shell environment, this situation is often handled by writing such preliminary procedures into a file that itself contains a call to start the desired job. This is referred to as a wrapper.
If users need to submit batch jobs that require this type of preliminary setup, LSF provides a job starter function at the queue level. A queue-level job starter allows you to specify an executable that will perform any necessary setup beforehand. One typical use of this feature is to customize LSF for use with Atria ClearCase environment (see `Support for Atria ClearCase' on page 275).
A queue-level job starter is specified in the queue definition (in the lsb.queues file) using the JOB_STARTER parameter. When a job starter is set up in this way, all jobs executed from this queue will be executed via the job starter (i.e., called by the specified job starter process rather than initiated by the batch daemon process). For example, the following might be defined in a queue:
Begin Queue
.
JOB_STARTER = xterm -e
.
End Queue
In this case, all jobs submitted into this queue will be run under an xterm terminal emulator.
The following are other possible uses of a job starter:
$USER_STARTER'; enables users to define their own job starters by defining the environment variable USER_STARTER. LSF also supports a user-definable job starter at the command level. See the LSF Batch User's Guide for detailed information about setting up and using a command-level job starter to run interactive jobs.
make clean;' causes make clean to be run prior to user job.
pvmjob or mpijob; allows you to run PVM or MPI jobs with LSF Batch, where pvmjob and mpijob are job starters for parallel jobs written in PVM or MPI.
A queue-level job starter is configured in the queue definition. See `Job Starter' on page 227 for details.
The difference between a job starter and a pre-execution command lies in the effect each can have on the job being executed. A pre-execution command must run successfully and exit, which signals the batch daemon to run the job. Because the pre-execution command is an unrelated process, it does not effect the execution environment of the job. The job starter, however, is the process responsible for invoking the user command, and as such, controls the job's execution environment.
Software licenses are valuable resources that must be utilized to their full potential. This section discusses how LSF Batch can help manage licensed applications to maximize utilization and minimize job failure due to license problems.
Many applications have restricted access based on the number of software licenses purchased. LSF can help manage licensed software by automatically forwarding jobs to licensed hosts, or by holding jobs in batch queues until licenses are available.
There are three main types of software license: host locked, host locked counted, and network floating.
Host locked software licenses allow users to run an unlimited number of copies of the product on each of the hosts that has a license. You can configure a boolean resource to represent the software license, and configure your application to require the license resource. When users run the application, LSF chooses the best host from the set of licensed hosts.
See `Changing LIM Configuration' on page 55 for instructions on configuring boolean resources, and `The lsf.task and lsf.task.cluster Files' on page 187 for instructions on configuring resource requirements for an application.
Host locked counted licenses are only available on specific licensed hosts, but also place a limit on the maximum number of copies available on the host. If an external LIM can get the number of licenses currently available, you can configure an external load index licenses giving the number of free licenses on each host. By specifying licenses>=1 in the resource requirements for the application, you can restrict the application to run only on hosts with available licenses.
See `Changing LIM Configuration' on page 55 for instructions on writing and using an ELIM, and `The lsf.task and lsf.task.cluster Files' on page 187 for instructions on configuring resource requirements for an application.
If a shell script check_license can check license availability and acquires a license if one is available, another solution is to use this script as a pre-execution command when submitting the licensed job.
% bsub -m licensed_hosts -E check_license licensed_job
An alternative is to configure the check_license script as a queue level pre-execution command. See `Queue-Level Pre-/Post-Execution Commands' on page 224 for more details.
It is possible that the license becomes unavailable between the time the check_license script is run, and when the job is actually run. To handle this case, the LSF administrator can configure a queue so that jobs in this queue will be requeued if they exit with value(s) indicating that the license was not successfully obtained. See `Automatic Job Requeue' on page 231.
A floating license allows up to a fixed number of machines or users to run the product at the same time, without restricting which host the software can run on. Floating licenses can be thought of as `cluster resources'; rather than belonging to a specific host, they belong to all hosts in the cluster.
Using LSF Batch to run licensed software can improve the utilization of the licenses - the licenses can be kept in use 24 hours a day, 7 days a week. For expensive licenses, this increases their value to the users. Also, productivity can be increased, as users do not have to wait around for a license to become available.
LSF can be used to manage floating licenses using the shared resources feature together with resource reservation and job requeuing. Both situations where all license jobs are run through LSF Batch and when licenses can be used outside of batch control are discussed.
If all jobs requiring licenses are submitted through LSF Batch, then LSF Batch could regulate the allocation of licenses to jobs and ensure that a job is not started if the required license is not available. A static resource is used to hold the total number of licenses that are available. The static resource is used by LSF Batch as a counter which is decremented by the resource reservation mechanism each time a job requiring that resource is started.
For example, suppose that there are 10 licenses for the Verilog package shared by all hosts in the cluster. The LSF Base configuration files should be specified as shown below. The resource is static-valued so an ELIM is not necessary.
lsf.shared
Begin Resource
RESOURCENAME TYPE INTERVAL INCREASING DESCRIPTION
verilog Numeric () N (Floating licenses for Verilog)
End Resource lsf.cluster.cluster Begin ResourceMap
RESOURCENAME LOCATION
verilog (10@[all])
End ResourceMap
The users would submit jobs requiring Verilog licenses as follows:
bsub -R 'rusage[verilog=1]' myprog
If a dedicated queue is defined to run Verilog jobs, then the LSF administrator can specify the resources requirements at the queue-level:
Begin Queue
QUEUE_NAME = q_verilog
RES_REQ=rusage[verilog=1]
End Queue
If the Verilog licenses are not cluster-wide and can only be used by some hosts in the cluster, then the resource requirement string should be modified to include the 'defined()' tag in the select section, as follows:
select[defined(verilog)] rusage[verilog=1]
For each job in the queue "q_verilog", LSF Batch will reserve a Verilog license before dispatching a job, and release the license when the job completes. The number of licenses being reserved can be shown using the bhosts -s command. One limitation of this approach is that if a job does not actually use the license then the licenses will be under-utilized. This could happen if the user mistakenly specifies that their application needs a Verilog license, or submits a non-Verilog job to a Verilog queue. LSF Batch assumes that each job indicating that it requires a Verilog license will actually use it, and simply subtracts the total number of jobs requesting Verilog licenses from the total number available to decide whether an additional job can be dispatched.
To handle the situation where application licenses are used by jobs outside of LSF Batch, an ELIM should be used to collect the actual number of licenses available instead of relying on a statically configured value. LSF Batch is periodically informed of the number of available licenses and takes this into consideration when scheduling jobs. Assuming there are a number of licenses for the Verilog package that can be used by all the hosts in the cluster, the LSF Base configuration files could be set up to monitor this resource as follows:
lsf.shared
Begin Resource
RESOURCENAME TYPE INTERVAL INCREASING DESCRIPTION
verilog Numeric 60 N (Floating licenses for Verilog)
End Resource lsf.cluster.clusterBegin ResourceMap
RESOURCENAME LOCATION
verilog ([all])
End ResourceMap
The INTERVAL in the lsf.shared file would indicate how often the ELIM was expected to update the value of the 'Verilog' resource (in this case every 60 seconds). Since this resource is shared by all hosts in the cluster, the ELIM would only need to be started on the master host. If the Verilog licenses can only be accessed by some hosts in the cluster, the LOCATION field of the "ResourceMap" section should be specified as ([hostA hostB hostC ...]). In this case an ELIM is only started on hostA.
The users would submit jobs requiring Verilog licenses as follows:
bsub -R 'rusage[verilog=1:duration=1]' myprog
LSF administrators can set up a queue dedicated to jobs that require Verilog licenses:
Begin Queue
QUEUE_NAME = q_verilog
RES_REQ=rusage[verilog=1:duration=1]
End Queue
The queue named q_verilog contains jobs that will reserve one Verilog license when it is started. Notice the duration specified (in minutes) is used to avoid the under utilization of shared resources. When duration is specified, the shared resource will be released after the specified duration expires. The reservation prevents the multiple jobs which are started in a short interval from over-using the available licenses. By limiting the duration of the reservation and using the actual license usage as reported by the ELIM, underutilization is also avoided and licenses used outside of LSF can be accounted for.
In situations where an interactive job outside the control of LSF Batch competes with batch jobs for a software license, it is possible that a batch job, having reserved the software license, may fail to start as the very license is intercepted by an interactive job. To handle this situation it is required that LSF Batch requeue the job for future execution. Job requeue can be achieved by using REQUEUE_EXIT_VALUES keyword in a queue's definition (see lsb.queues(5)). If a job exits with one of the values in the REQUEUE_EXIT_VALUES, LSF Batch will requeue the job. For example, jobs submitted to the following queue will use Verilog licenses:
Begin Queue
QUEUE_NAME = q_verilog
RES_REQ=rusage[verilog=1:duration=1]
# application exits with value 99 if it fails to get license
REQUEUE_EXIT_VALUE = 99
JOB_STARTER = lic_starter
End Queue
All jobs in the queue are started by lic_starter, which checks if the application failed to get a license and exits with an exit code of 99. This will cause the job to be requeued and the system will attempt to reschedule it at a later time. lic_starter can be coded as follows:
#!/bin/sh
# lic_starter: If application fails with no license, exit 99,
# otherwise, exit 0. The application displays
# "no license" when it fails without license available.
$* 2>&1 | grep "no license"
if [ $? != "0" ]
then
exit 0 # string not found, application got the license
else
exit 99
fi
There are numerous ways to build queues. This section provides some examples.
You want to dispatch large batch jobs only to those hosts that are idle. These jobs should be suspended as soon as an interactive user begins to use the machine. You can (arbitrarily) define a host to be idle if there has been no terminal activity for at least 5 minutes and the 1 minute average run queue is no more than 0.3. The idle queue does not start more than one job per processor.
Begin Queue
QUEUE_NAME = idle
NICE = 20
RES_REQ = it>5 && r1m<0.3
STOP_COND = it==0
RESUME_COND = it>10
PJOB_LIMIT = 1
End Queue
If a department buys some fast servers with its own budget, they may want to restrict the use of these machines to users in their group. The owners queue includes a USERS section defining the list of users and user groups that are allowed to use these machines. This queue also defines fairshare policy so that users can have equal sharing of resources.
Begin Queue
QUEUE_NAME = owners
PRIORITY = 40
r1m = 1.0/3.0
FAIRSHARE = USER_SHARES[[default, 1]]
USERS = server_owners
HOSTS = server1 server2 server3
End Queue
On the other hand, the department might want to allow other people to use its machines during off hours so that the machine cycles are not wasted. The night queue only schedules jobs after 7 p.m. and kills jobs around 8 a.m. every day. Jobs are also allowed to run over the weekend.
To ensure jobs in the night queue do not hold up resources after the run window is closed, TERMINATE_WHEN is defined as WINDOW so that when the run window is closed, jobs that have been started but have not finished will be killed.
Because no USERS section is given, all users can submit jobs to this queue. The HOSTS section still contains the server host names. By setting MEMLIMIT for this queue, jobs that use a lot of real memory automatically have their time sharing priority reduced on hosts that support the RLIMIT_RSS resource limit.
This queue also reserves swp memory of 40MB for the job and this reservation decreases to 0 over 20 minutes after the job starts.
Begin Queue
QUEUE_NAME = night
RUN_WINDOW = 5:19:00-1:08:00 19:00-08:00
PRIORITY = 5
RES_REQ = ut<0.5 && swp>50 rusage[swp=40:duration=20:decay=1]
r1m = 0.5/3.0
MEMLIMIT = 5000
TERMINATE_WHEN = WINDOW
HOSTS = server1 server2 server3
DESCRIPTION = Low priority queue for overnight jobs
End Queue
Some software packages have fixed licenses and must be run on certain hosts. Suppose a package is licensed to run only on a few hosts that are tagged with product resource. Also suppose that on each of these hosts, only one license is available.
To ensure correct hosts are chosen to run jobs, a queue level resource requirement `type==any && product' is defined. To ensure that the job gets a license when it starts, the HJOB_LIMIT has been defined to limit one job per host. Since software licenses are expensive resources that should not be under-utilized, the priority of this queue has been defined to be higher than any other queues so that jobs in this queue are considered for scheduling first. It also has a small nice value so that more CPU time is allocated to jobs from this queue.
Begin Queue
QUEUENAME = license
NICE = 0
PRIORITY = 80
HJOB_LIMIT = 1
RES_REQ = type==any && product
r1m = 2.0/4.0
DESCRIPTION = Licensed software queue
End Queue
The short queue can be used to give faster turnaround time for short jobs by running them before longer jobs.
Jobs from this queue should always be dispatched first, so this queue has the highest PRIORITY value. The r1m scheduling threshold of 2 and no suspending threshold mean that jobs are dispatched even when the host is being used and are never suspended. The CPULIMIT value of 15 minutes prevents users from abusing this queue; jobs running more than 15 minutes are killed.
Because the short queue runs at a high priority, each user is only allowed to run one job at a time.
Begin Queue
QUEUE_NAME = short
PRIORITY = 50
r1m = 2/
CPULIMIT = 15
UJOB_LIMIT = 1
DESCRIPTION = For jobs running less than 15 minutes
End Queue
Because the short queue starts jobs even when the load on a host is high, it can preempt jobs from other queues that are already running on a host. The extra load created by the short job can make some load indices exceed the suspending threshold for other queues, so that jobs from those other queues are suspended. When the short queue job completes, the load goes down and the preempted job is resumed.
Some special-purpose computers are accessed through front end hosts. You can configure the front end host in lsb.hosts so that it accepts only one job at a time, and then define a queue that dispatches jobs to the front end host with no scheduling constraints.
Suppose hostD is a front end host:
Begin Queue
QUEUE_NAME = front
PRIORITY = 50
HOSTS = hostD
JOB_STARTER = pload
DESCRIPTION = Jobs are queued at hostD and started with pload command
End Queue
To interoperate with NQS, you must configure one or more LSF Batch queues to forward jobs to remote NQS hosts. An NQS forward queue is an LSF Batch queue with the parameter NQS_QUEUES defined. The following queue forwards jobs to the NQS queue named pipe on host cray001:
Begin Queue
QUEUE_NAME = nqsUse
PRIORITY = 30
NICE = 15
QJOB_LIMIT = 5
CPULIMIT = 15
NQS_QUEUES = pipe@cray001
DESCRIPTION = Jobs submitted to this queue are forwarded to NQS_QUEUES
USERS = all
End Queue
The lsb.hosts file defines host attributes. Host attributes also affect the scheduling decisions of LSF Batch. By default LSF Batch uses all server hosts as configured by LIM configuration files. In this case you do not have to list all hosts in the Host section. For example:
Begin Host
HOST_NAME MXJ JL/U swp # This line is keyword(s)
default 2 1 20
End Host
The virtual host name default refers to each of the other hosts configured by LIM but is not explicitly mentioned in the Host section of the lsb.hosts file. This file defines a total allowed job slot limit of 2 and a per user job limit of 1 for every batch server host. It also defines a scheduling load threshold of 20MB of swap memory.
In most cases your cluster is heterogeneous in some way, so you might have different controls for different machines. For example:
Begin Host
HOST_NAME MXJ JL/U swp # This line is keyword(s)
hostA 8 2 ()
hppa 2 () ()
default 2 1 20
End Host
In this file you add host type hppa in the HOST_NAME column. This will include all server hosts from LIM configuration that have host type hppa and are not explicitly listed in the Host section of this file. You can also use a host model name for this purpose. Note the `()' in some of the columns. It refers to undefined parameters and serves as a place-holder for that column.
lsb.hosts file can also be used to define host groups and host partitions, as exemplified in `Sharing Hosts Between Two Groups' on page 115.