When managing critical jobs it is important to ensure that the jobs run properly. When problems arise with the scheduling and execution of a job, it is necessary that some actions be taken to fix the problem. An alarm specifies how a notification should be sent in the event of such a problem.
LSF JobScheduler provides flexible ways to handle failures and exceptions so that you can define what to do when certain exceptions happens. Failures of job processing are defined in terms of exceptions and handling of these failures are defined in terms of exception handlers. An alarm is triggered as a result of the exception handler alarm().
LSF JobScheduler monitors exceptions as defined by exception functions. Each exception function has a name and possibly parameters that allow users to further customize exceptions on a per job basis.
The exception functions are used when creating a job to tell LSF JobScheduler what exceptions to watch for for this particular job. You need to understand the behaviour of your application properly to determine what is considered an exception for your job. The following are the exception functions supported by LSF JobScheduler:
missched()
The job has a time event associated with it, and the job was not able to start while the time event was in active status. This function has no parameter associated with it.
There can be many different reasons why your job can miss its schedule. For example, you may have specified a resource requirement for your job that was not satisfied while the time event was active. Or the duration of the time event is too short to find a host that can process the job. It is also possible that you have specified other dependency conditions for the job that were not satisfied while the time event was active.
To minimize such exceptions, you should carefully examine your schedule and conditions, and make sure that in most cases the conditions will be met when the time event is active.
abend(ec1, ec2, ...)
The job has exited with one of the given exit codes. The list of parameters is a list of exit codes in the range of -128 to 127. Each parameter can be either one exit code, or a range of codes in the form of c1-c2.Most applications, when finishing successfully, should exit with exit code 0. However, some applications are not programmed to handle exit codes properly. For example, some applications exit with a non-zero value even if it finishes successfully. You should carefully check your application and determine the behaviour of your job, and define your own job-specific abnormal termination accordingly. Sometimes you may have to wrap your application with a script to make its exit code reflect success or failure.
overrun(max_time)
The job has run for too long. The parameter specifies the maximum allowed run time in minutes. This function can be used to detect a situation where a job runs away, or when a job hangs. For example, if your job should finish in less than 10 minutes, then if the job has run for 2 hours, something must be wrong. underrun(min_time)
The job has finished too soon. The parameter specifies the minimum required run time in minutes. This function is used to detect situations where a job finishes prematurely.
startfail()
A problem in starting the job has occurred and thus the job was unable to start. This function has no parameter.
Typical reasons for this exception include lack of system resources, e.g. process table full on the execution host, or file system not mounted properly thus the execution host cannot set up the execution environment for the job.
hostfail()
The host on which a job was started went down. This function has no parameter.
cantrun()
System detects that it is impossible to run the job because various dependencies cannot be satisfied. This exception also happens ifstartfail()exception occurs 20 times in a row.
A typical example of a job that triggers cantrun() exception is a job that depends on an job event, but that job has been deleted from the system so that the job event never happens.
For each exception condition of a job, a corrective action can be associated with the job which is automatically invoked when the specified exception happens. Such an action is called an exception handler in LSF JobScheduler. The handler can try to resolve the problem automatically or inform the user/administrator that the problem was detected. The currently available handlers are:
rerun()Rerun the job. In many situations, re-running the job will fix the problem. This handler is only relevant for exception conditionsunderrun()andabend(). It is possible that the job will be re-run on a different host depending on the dynamic resource availability and the job's resource requirement.
alarm(severity, alarm_name)
Raise an alarm with the given severity. The alarm name identifies which alarm should be triggered. The valid alarm names are configured by your LSF administrator and can be viewed bybalarmscommand. See `Alarms' on page 130 for details of alarms.
kill()- This action causes the current execution of the job to be terminated. This action can only be specified for theoverrun()exception.
setexcept(event_name)Set the exception event identified byevent_nameto active. The parameterevent_nameis the name of an event that is created by another job as an exception event dependency condition. See `Job Exception Event Dependency' on page 89 for details.
This handler is an interface for external exception handlers. All other exception handlers are built-in handlers. By defining jobs that respond to the job exception event, arbitrary actions can be invoked to handle the exception. This is useful when none of the built-in handlers can handle your particular error.
With the exception handling mechanism provided in LSF JobScheduler, you can tune your schedules so that all failures are taken care of automatically, and minimum human intervention is necessary. This section goes through some typical steps of implementing error handling measures for your schedules.
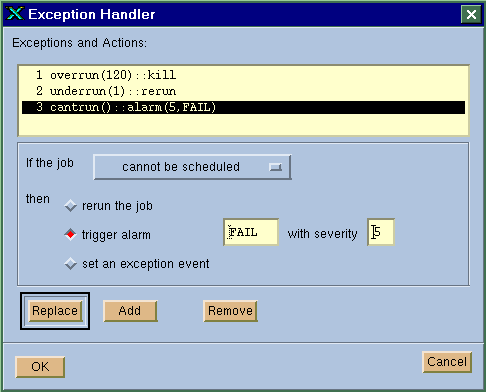
When you create a job, you can specify what exceptions you want LSF JobScheduler to watch for, and how you want to handle the exceptions when they happen. Click on the "Exception Handler" button in the job submission window, as shown in Figure 11 on page 64, to display the exception handler window, as shown in Figure 36.
You can specify any number of exceptions, each with a handler.
In the example in Figure 36, three exceptions for the job have been defined, each with a different built-in exception handler. The first exception is overrun(120) which tells LSF JobScheduler that this job is not to run for more than 120 minutes. If this happens, the job should be killed, as indicated by the handler kill(). The second exception is underrun(1) which tells LSF JobScheduler that this job should not run for less than 1 minute. If this happens, the job should be re-run, as specified by the handler rerun(). The last exception is cantrun(), which tells LSF JobScheduler to raise the alarm named "FAIL" with severity 5 if the job is impossible to schedule.
For details on raising an alarm handler, see `Alarms' on page 130.
Figure 36. Exception Handler Definition Window
If none of the built-in handlers serve your purpose, you can set up your job so that external exception handlers or recovery jobs can be automatically invoked to correct the error. In order to achieve this, an exception event must be defined together with the recovery job. Multiple error recovery jobs can be defined to respond to the same job exception event.
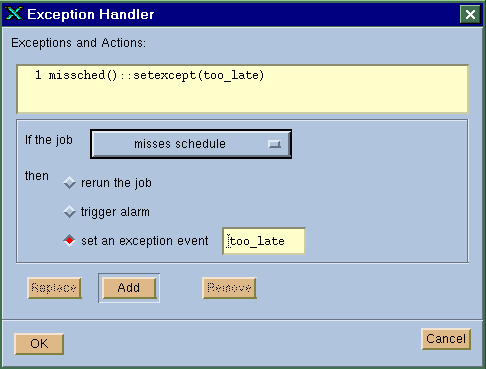
First, you define the main job using the job submission window and define "setexcept()" to be the exception handler, as shown in Figure 37. By defining the exception handler as setexcept(), the job exception event "too_late" is set to active status as soon as the exception "missched()" is detected for the current job. The status change of event "too_late" can then trigger all recovery jobs that depend on the "too_late" job exception event.
Figure 37. Setting an Exception Event to Trigger Recovery Jobs
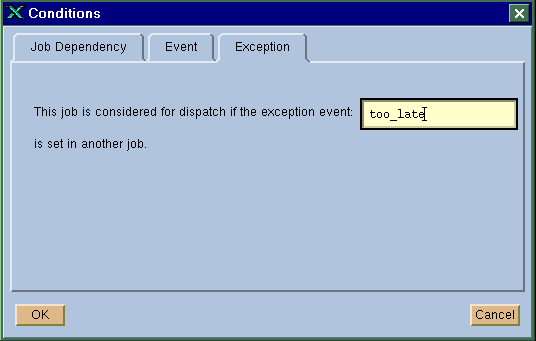
To define an error recovery job that responds to the job exception event, click on the "Conditions" button in the job submission window as shown in Figure 11 on page 64, and then click on the "Exception" tab. This brings up the exception condition window as shown in Figure 38. Enter the name of the job exception event in the window to make this job respond to the event.
As soon as you define a job that depends on the named exception event, the event is created inside LSF JobScheduler which then starts to monitor the status of the event. Whenever the exception happens, the event will be set to ACTIVE as a result of the setexcept() handler of the main job, thus triggering the recovery job to run.
Note that you can define more than one recovery job to respond to the same exception. On the other hand, you can also have one recovery job to be the handler for many main jobs, as long as they all trigger the same exception event.
It is possible to set your job such that some exceptions are handled by built-in exception handlers while others handled by recovery jobs. As shown in Figure 36, you can have a different exception handler for each exception condition.
Figure 38. Setting a Job to Respond to an Exception Event
Although you can use the graphical tools for all exception handling, LSF JobScheduler also allows you to define exception handling from the command line using the bsub command.
To specify an exception handler for a job, use the "-X" option of the bsub command. The format of the -X option is:
exception_cond([params])::action
where exception_cond is one of the exception functions discussed in `Exceptions' on page 123, params are possible parameters associated with the exception function, and "action" is one of the exception handlers discussed in `Exception Handlers' on page 125.
The following example sets an exception handler for a job which will result in an alarm being triggered if the job exits with an exit code of 10:
% bsub -X "abend(10)::alarm(5, pageadmin)" [other options] myjob
Multiple handlers can be specified by repeating the -X option:
% bsub -X "abend(10)::alarm(5, pageadmin)" -X /
"abend(1)::rerun" [other options] myjob
To define a job that responds to a job exception event, use the -w option of the bsub command. The following example defines two jobs. The first job is the main job and the second job is a recovery job that is triggered when the first job has failed to finish within 60 minutes after starting.
% bsub -X "overrun(60)::setexcept(too_long)" [other options] realJob
% bsub -w "exception(too_long)" [other options] recoveryJob
An alarm specifies how a notification should be sent in the event of an exception. An alarm is triggered as a result of the exception handler alarm(). If you want to trigger an alarm as a result of a job failure, you must specify an alarm name and a severity number using the alarm() exception handler.
When the alarm() handler is called, LSF JobScheduler invokes a site-installable executable that must be named raisealarm. This executable is a reporter which raises the specified alarm. LSF JobScheduler invokes the raisealarm executable with four arguments: alarm name, severity, source, and context. The source argument is the name of the job that has triggered the alarm. The context tells the detail of the alarm, for example,
overrun Job[1529] User[user1] Queue[normal]
LSF JobScheduler comes with a default raisealarm executable that will do a few things when an alarm is triggered. It first logs a record for the alarm incident in a log file. It then initiates a notification method defined in the alarm configuration. LSF JobScheduler also re-sends the notification if an open alarm has not been acknowledged within a given time.
The raisealarm executable bundled with LSF JobScheduler can be configured to send a notification via email, or invoke a site-replaceable notification executable.
If your site is using the raisealarm executable bundled with LSF JobScheduler, your LSF administrator can define alarms through a configuration file. To see what alarms are currently configured by your LSF administrator, run the balarms command with the def option. For example:
% balarms def
ALARM: pageadmin
-- Page the administrator
NOTIFICATION:
METHOD: CMD[ /usr/local/bin/pageadmin]
RETRIES: Every 30 minutes. Maximum of 10 retries
EXPIRATION:
Incident automatically expires after 6000 minutes
---------------------------------------------------
ALARM: MailAdmin
-- Inform admin of minor problems
NOTIFICATION:
METHOD: EMAIL[admin]
RETRIES: Every 30minutes. Maximum 5 retries
EXPIRATION:
Incident automatically expires after 3000 minutes
Each alarm has a name and a notification method defined. LSF JobScheduler supports notification through email or using a configured command which can be used to send a notification via a pager, consoles, etc. The administrator can configure an alarm to periodically resend the notification if the alarm is not acknowledged. You can also view alarm configuration from the xbalarms GUI.
Each time an alarm is triggered, a new alarm record is added to a log file. The alarm record contains the name of the alarm, when it was triggered, the job that has triggered the alarm, and some additional details.
You can view and manipulate alarms by using the balarms command or the xbalarms GUI. Figure 39 shows a sample listing of outstanding alarm incidents using the xbalarms GUI.
Figure 39. Alarm Monitoring Window
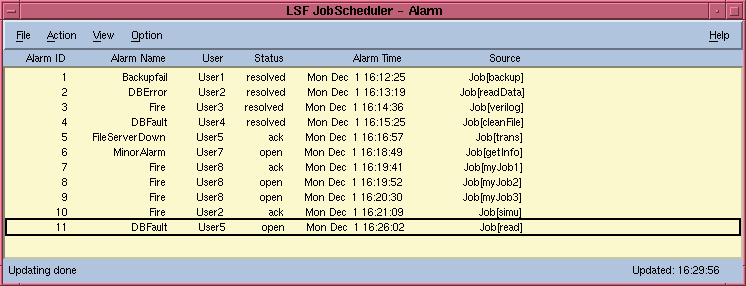
The possible states of an alarm are:
open
The alarm is triggered, but has not been acknowledged.
ack
The alarm is acknowledged by some user, which should indicate that the user has processed the alarm situation.
resolved
The alarm situation has been resolved. This means that this alarm has been handled and no longer needs attention.
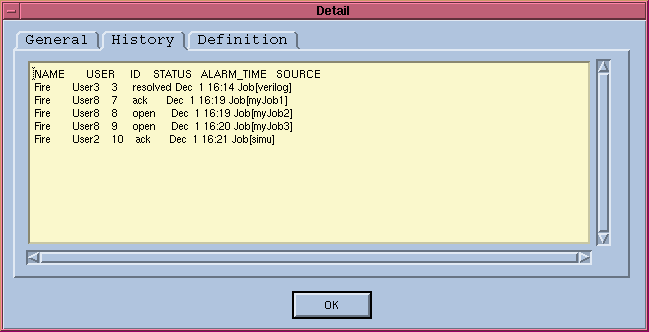
You can view the details of each alarm by double-clicking on the selected alarm. This will bring up a popup window with alarm details, which allows you to see alarm configuration, alarm status, and alarm history. Figure 40 is an example of the alarm history window of the xlsbalarms GUI.
To acknowledge or resolve an alarm, select the alarm and choose the appropriate action from the "Action" menu. This will bring up a window prompting you for a resolving or acknowledging message. The message you enter will be logged so that other people will be able to see your solutions in the alarm detail window.
Figure 40. Alarm History Window
The above alarm system interface is valid if your site is using the bundled raisealarm executable of LSF JobScheduler. Your site may choose to handle alarms generated by JobScheduler jobs through another alarm management module which may interpret the severity field differently. In that case, you should refer to local documentation for alarm management.